
Support for the SQL/MED standard was introduced in PostgreSQL 9.1 (2011). Four years later, we now have more the 70 Foreign Data Wrappers (FDW) available,
which you can use to read and write on any type of data storage : Oracle, MongoDB, XML files, Hadoop, Git repos, Twitter, you-name-it, …

A few days ago, during FOSDEM I attended a talk by my colleague Ronan Dunklau about Foreign Data Wrappers in PostgreSQL : Where are we now ?. Ronan is the author of the multicorn extension and during his talk I couldn’t help but thinking that multicorn is probably one of the most underrated piece of code in the PostgreSQL Community. As a quick exercise I started to count all the PostgreSQL FDW I knew about… and soon realized there were too many to fit my small memory.
So I went back to the FDW page in the PostgreSQL wiki. I started to update and clean up the catalog of all the existing FDW and ended with a list of 70+ wrappers for PostgreSQL…
Lessons learned
During this process I learned a few things :
-
Almost all the major RDBMS are covered, except DB2. Strangely DB2 is also the only other RDBMS with a SQL/MED implementation. I’m not sure if those 2 facts are related or not.
-
One third of the FDW are written in Python and based on Multicorn. The others are “native” C wrappers. Obviously C wrappers are prefered for the database wrappers (ODBC, Oracle, etc.) for performance reasons. Meanwhile Multicorn is mostly used for query web services (S3 storage,RSS files, etc.) and specific data formats (Genotype files, GeoJSON, etc.)
-
I’m not sure they were meant to be this way, but Foreign Data Wrapper are also used to innovate. Some wrappers are diverted from the original purpose to implement new features. For instance, CitusDB has released a FDW-based column-oriented storage, others wrappers are going in more exotic directions such as an OS level stat collector, a GPU accelerator for seq scans or a distbributed parallel query engine, … Most of these projects are not suited for production, of course. However it shows how easy you can implement a Proof of Concept and how versatile this technology is…
-
The PGXN distribution network doesn’t seem to be well-kown among FDW developpers. Only 20% of the wrappers are available via PGXN. Or maybe developers are too lazy to package their extensions ?
-
The success of PostgreSQL SQL/MED implementation comes with a drawback. My guess is that there will be more 100 data wrappers available by the end of 2015. For some data source like mongodb or LDAP, there’s already several different wrappers, not to mention the procession of Hadoop connectors :) In the long term, PostgreSQL end users might get confused by all these wrappers and it will be hard to know which one is maintained and which one is obsolete… The wiki page tries to answer that problem but there may be other solutions to provide accurate information to the end user… Maybe we need a Foreign Data Wrapper that would list all the Foreign Data Wrappers :)
The next big thing : IMPORT FOREIGN SCHEMA
Moreover there’s still a big limitation the current SQL/MED implementation : metadata. Right now, there’s no simple way to use the schema introspection capabilities of the foreign data source (if any). This means you have to create all the foreign tables one by one. When you want to map all the tables of a distant database, it can be time-consuming and error-prone. If you’re connecting to a remote PostgreSQL instance you can use tricks like this one but objectively this is a job the wrapper should do by itself (when possible).
Here comes the new IMPORT FOREIGN SCHEMA statement ! This new feature was written by Ronan Dunklau, Michael Paquier and Tom Lane. You can read a quick demo at Michael’s blog. This will be available in the forthcoming PostgreSQL 9.5.
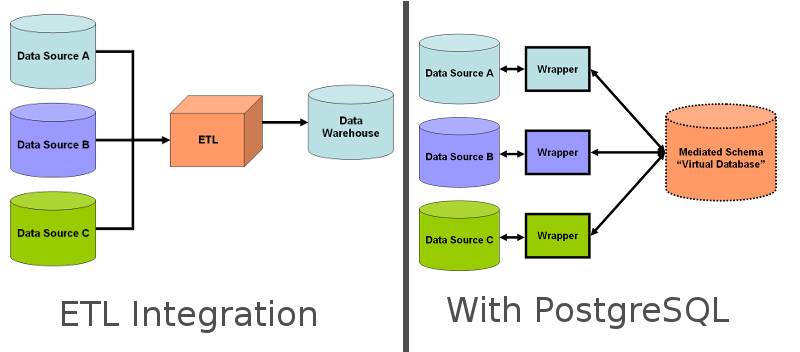
This is a huge improvement ! This IMPORT feature and the dozens of Wrappers available are key factors : PostgreSQL is becoming a solid Data Integration Plateform and it reduces the need for external ETL software.
Links :
blog comments powered by Disqus